- Published on
Datajudge: A library for data tests across data sources
- Authors
Datajudge is a Python library for expressing and testing expectations against data from database. In particular, it allows for comparisons between distinct sources, e.g. database tables, of tabular data. In doing so, it can judge whether a transition from one data source to another is to be considered legitimate or not.
Why
At QuantCo, we seek to solve our customer’s core problems by leveraging data. Yet, it seems clear that when relying on data for downstream challenges, data quality is of paramount relevance. It directly impacts results. To quote MIT’s Michael Stonebreaker
[…] without clean data, or clean enough data, your data science is worthless.
We have come to rely on and appreciate and foster data tests as a means to ensure and improve data quality.
Testing has prevailed as an essential component of modern Software Engineering. It allows for reasoning about the correctness of code or data. In particular, if code or data are not static but change over time — i.e. in most settings — having a thorough test suite enables automation and faster development. If data-generating code is thoroughly tested, one can often have substantial confidence in the quality of the data. Yet, in many scenarios, the user of data does not necessarily have access to the data-generating code. In such a situation it can be very useful to test the data, in lieu of the inaccessible code. We refer to this approach as ‘data tests’, in contrast to ‘code tests’. Note that code tests are typically executed before code is run, while data tests are typically executed after the data is generated but before it is used in downstream tasks.
Conversely, specifying data tests can also be a way to improve the understanding of the underlying data. Cycling between adapting data tests and evaluating their respective results can be an iterative way of testing hypotheses against data. Such a workflow can enable and foster discoveries of data properties.
Truth be told: we certainly haven’t invented the concept of data tests. Other libraries, such as Great Expectations, provide assistance when it comes to the specification and execution of data tests. Existing solutions provide ways to assert properties — we like to call them constraints — of the data relative to a fixed reference value derived from expert knowledge. For example, with the help of domain knowledge about heart rates, one might want to express that values representing heart rates should lie between lower bound of 0 and upper bound of roughly 480, plus some epsilon, beats per minute. Yet, we couldn’t find satisfying tooling to test consistency of data relative to other data. This need arose in two conceptually distinct use cases.
Use case 1: Data changes over time
It is common for many business contexts to receive data packages or data dumps in regular intervals, for example, once a week. Working in many such scenarios, we would often like to ingest these data deliveries automatically - using it to improve our data-driven decision making. In order to do so, we intend to first reliably assess whether the data’s quality is on par. Different causes for a deterioration of data quality exist:
- There could be a logical problem this new batch of data. This could, for instance, be caused by a bug in the data-generating code.
- There might be a technical problem in the transmission of the data.
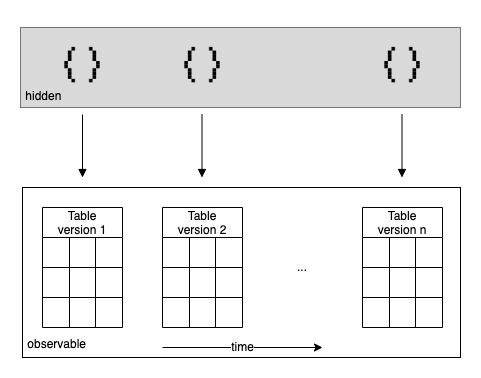
In order to assess data quality in an automated fashion, we might ask questions such as:
- Are all rows from version 1 still present in version 2?
- Has the number of rows grown by at most 10% from version 1 to version 2?
- Has the column definition remained the same between version 1 and version 2?
- Has the mean of the reported sales fluctuated by at most .5% between version 1 and version 2?
- Are there new or missing values in categorical valued columns that might affect the performance of models currently in use?
Use case 2: Consistency between ‘different kinds’ of data
We just saw an example of how the same ‘kind’ of data, merely a time difference apart, can be used to validate each other. Yet, even if two data sources are not of the same kind, they can still be useful to validate properties of each other. For instance, we might observe some data which serves as an input to a transformation as well as the data that results from this very transformation. If, moreover, we don’t have access (or simply cannot test, for a different reason) to the code which transforms the data, we might want to use information of the input data to validate the output data.
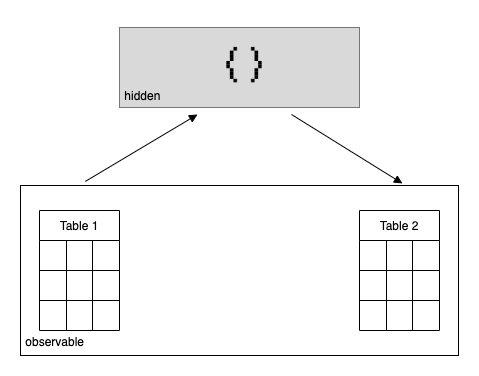
Concretely, if input data revolves around individual commercial transactions and output data around aggregated commercial transactions (e.g. aggregation by vendor and buyer pair), we might want to ask questions such as:
- Have all unique transaction participant ids from the aggregated dataset also previously occurred as in the individual transaction dataset?
- Is the minimum transaction amount at least as high in the aggregated dataset as the minimum transaction amount in the original dataset?
- Conditioned on an aggregate consisting of exactly one transaction, are all such ‘aggregate’ transactions still exactly equal to the corresponding individual transaction?
Why not use database constraints?
Some database management systems allow for internal constraints, e.g. check constraints. Yet, they typically lack features and functionalities we have come to appreciate with Datajudge:
- They lack the capability to compare different data sources - internal database constraints typically target a single column or table.
- They are designed to operate on a ‘row-level’, meaning that they cannot make statements about an entire column. While they might be able to ensure that every row of an integer column is strictly positive, they cannot evaluate the predicate of at least 80% of the column’s rows being strictly positive.
- They often don’t allow for useful complexity such as conditioning and error tolerances - more on that below.
- They lead to a very different workflow - forcefully interrupting the database population currently running in case of a constraint violation. Managing control flow and integrating this into developer and CI/CD workflows can be trickier than using Datajudge with pytest.
How
Datajudge can be conveniently installed with conda or mamba
conda/mamba install datajudge -c conda-forgeor pip
pip install datajudgeIn order to specify constraints on data, a user first has to define where the data originates from.
This is done by instantiating a Requirement object.
In our example we have two data sources: an archived version of a table companies as well as a current version of a table companies.
from datajudge import BetweenRequirement
requirement = BetweenRequirement.from_tables(
db_name1="example",
table_name1="companies_archive",
db_name2="example",
table_name2="companies",
)Once both to be compared data sources are defined, one can express a constraint between both tables.
Here, we want to express that the name values of the first table, the archive, are all contained in the second table, the current version.
requirement.add_row_subset_constraint(columns1=['name'], columns2=['name'])Please have a look at the example in our documentation if you’re curious.
Once such constraints are expressed in a Python file, we provide an integration to simply test them with pytest. This comes with the advantage of being able to use pytest’s rich functionalities - from subselection over early termination to report generation with pytest-html. Generating reports has proven particularly useful for sharing results with other people and archiving.
Under the hood, Datajudge generates SQL queries by translating the constraints into SQLAlchemy expressions. Once a test is executed, these are run against database and results compared to expected values.
More features
In addition to its key functionality — comparison between data sources — Datajudge comes with further functionalities.
- Single data source: Datajudge also offers testing constraints against a single data source to fixed reference values, just like other data test libraries do.
Using the same scenario from above, we could express that at least 90% of the rows from table
companies’num_employeescolumn lie between user-defined lower bounds 10 and 150.000.
from datajudge import WithinRequirement
requirement_within = WithinRequirement(db_name="example", table_name="companies")
req_within.add_numeric_between_constraint(
column="num_employees",
lower_bound=10,
upper_bound=150000,
min_fraction=.9,
)- Conditioning: Datajudge provides functionality to restrict the evaluation of a constraint on a subset of rows satisfying a particular logical condition. We could, for instance, add a condition to eliminate rows with 0 values from the latter constraint evaluation.
from datajudge import Condition
condition = Condition(raw_string="num_employees > 0")
requirement_within.add_numeric_between_constraint(
column="num_employees",
lower_bound=10,
upper_bound=150000,
min_fraction=.9,
condition=condition,
)- Tolerances: Often we don’t expect data to entirely satisfy constraints expressed.
Datajudge anticipates this need by allowing for tolerances, explicitly allowing an absolute or relative number of violations.
E.g., in the example from before, we could add a tolerance indicating that we accept losing .1% of the rows in column
namesfrom the archive to the current table:
requirement.add_row_subset_constraint(
columns1=['name'],
columns2=['name'])
constant_max_missing_fraction=0.001,
)- Useful assertion messages: While it is of great value to be aware of the existence of a problem, it is of even greater value to fix that problem fast. In order to accelerate this process, Datajudge seeks to provide useful assertion messages, often coming with counterexamples to the assumed expectation: “0.25 > 0 of rows of companies’s column ‘name’ are not in companies_archive’s column ‘name’ - e.g. for ‘name’ = Apple.”
- Logging of built queries: Along test results, Datajudge logs the queries used for testing constraints.
This can be very useful for diving right into the data debugging process.
Datajudge is currently tested against Snowflake, Postgres and MS SQL.
At the same time, thanks to a mostly sql dialect agnostic backend, we would hope for it to work to a large extent with other sql dialects and relational database management systems.
# Remarks
* Datajudge is open source and licensed under BSD 3-Clause and on [github](https://github.com/Quantco/datajudge).
* This project has been collaborative work across projects and teams.