- Published on
Fixing a Snowflake performance issue around introspection
- Authors
When running the integration test suite of a data validation tool against a Snowflake instance, we saw a massive slow-down compared to Postgres or MS SQL.
We almost fully recovered from the regression by caching a SQLAlchemy call that triggered extremely slow metadata-related queries.
At QuantCo, we develop a library to perform validation or tests for data stored in relational databases. And although quite interesting in itself, this post is not about the tool but a performance issue we encountered when trying to use it against a Snowflake database.
Snowflake is a database as a service.
Fortunately, the company behind it provides a Python “driver” and, more importantly for us, an extension to SQLAlchemy.
Using this extension allows us to use our data validation library straightforwardly with Snowflake as a backend.
However, we encountered quite a surprising issue around the execution performance of the integration test suite.
Whereas for Postgres and MS SQL, the duration of the integration test is about 2 minutes, for Snowflake, it took close to 14 minutes.
As an analytics database, Snowflake is optimized for reading large amounts of data.
Before a query is executed, a lot of computational effort is spent on planning/optimizing its execution.
The planning time gets amortized by the amount of data it processes.
However, for the test suite, the data contained very few columns (<5) and few rows (<20).
The image below shows the details of the execution of a representative SELECT query generated by the library. There we can see that the duration is below 30 milliseconds.
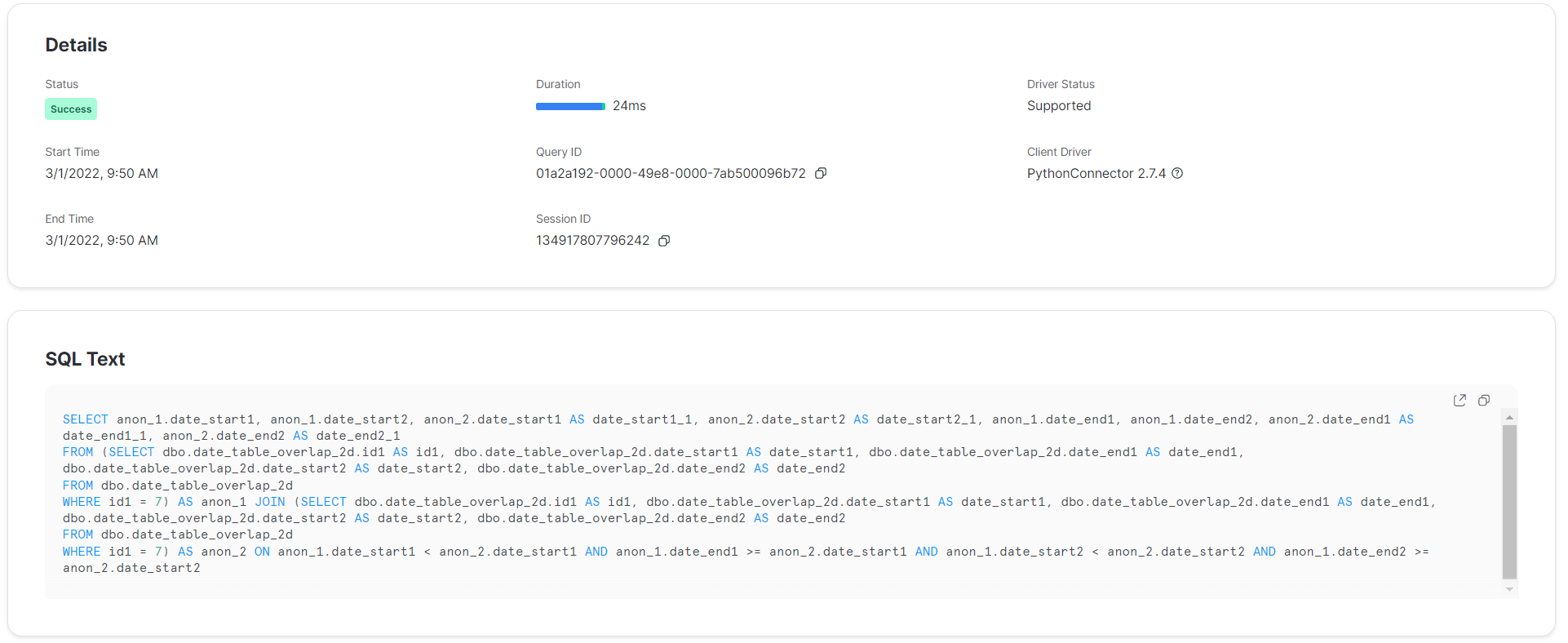
We were not expecting performance to be on par with Postgres, but never seven times longer. We could have left it there; 14 minutes is long but not too bad. On the other hand, a long testing suite reduces developer productivity and increases costs.
The first naive hypothesis was that perhaps the compute power assigned to run the queries triggered by the integration test suite was just too small. Since changing that is extremely easy, we tried that first. Thus, we switched to the next level, and we saw a whopping improvement of about 1 minute. Not precisely the improvement we were looking for.
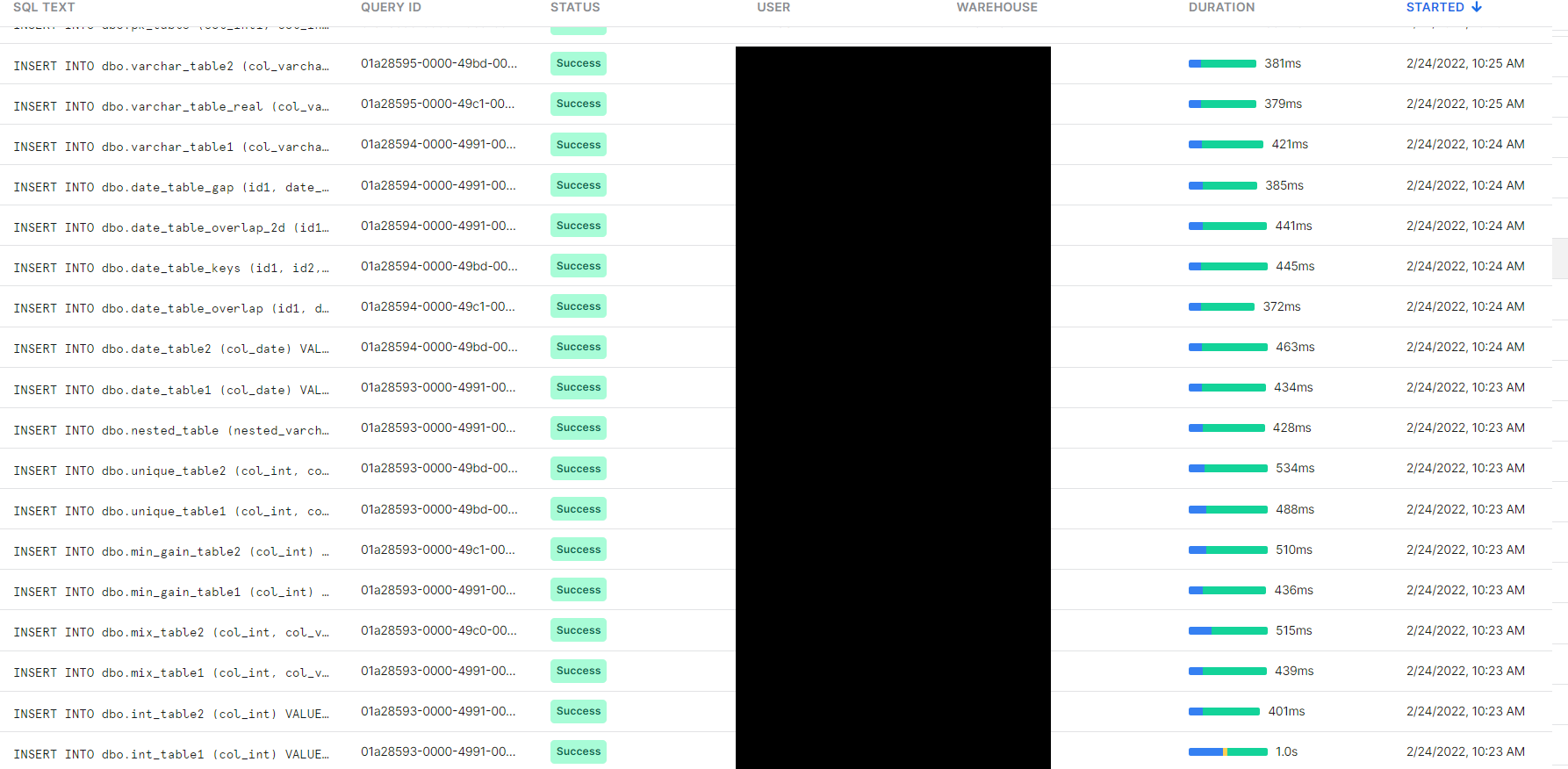
Fortunately, Snowflake provides a UI where a history of the executed queries can be inspected.
This UI provides some information like the result, the entire query, and duration time.
With that tool, we set to confirm the second hypothesis, that since Snowflake is optimized for reading, the INSERT queries were taking too long.
And indeed, they were taking long, anywhere between 0.3 and 1 second.
However, this does not account for the majority of the time since we create only about 20 tables.
So, being more thoughtful in producing the data would not give us much of a performance improvement.
While looking at the history of executed queries, we saw some particular-looking queries taking quite some time. In particular, the query
SELECT /* sqlalchemy:_get_schema_columns */
ic.table_name,
ic.column_name,
ic.data_type,
ic.character_maximum_length,
ic.numeric_precision,
ic.numeric_scale,
ic.is_nullable,
ic.column_default,
ic.is_identity,
ic.comment
FROM information_schema.columns ic
WHERE ic.table_schema='DBO'
ORDER BY ic.ordinal_position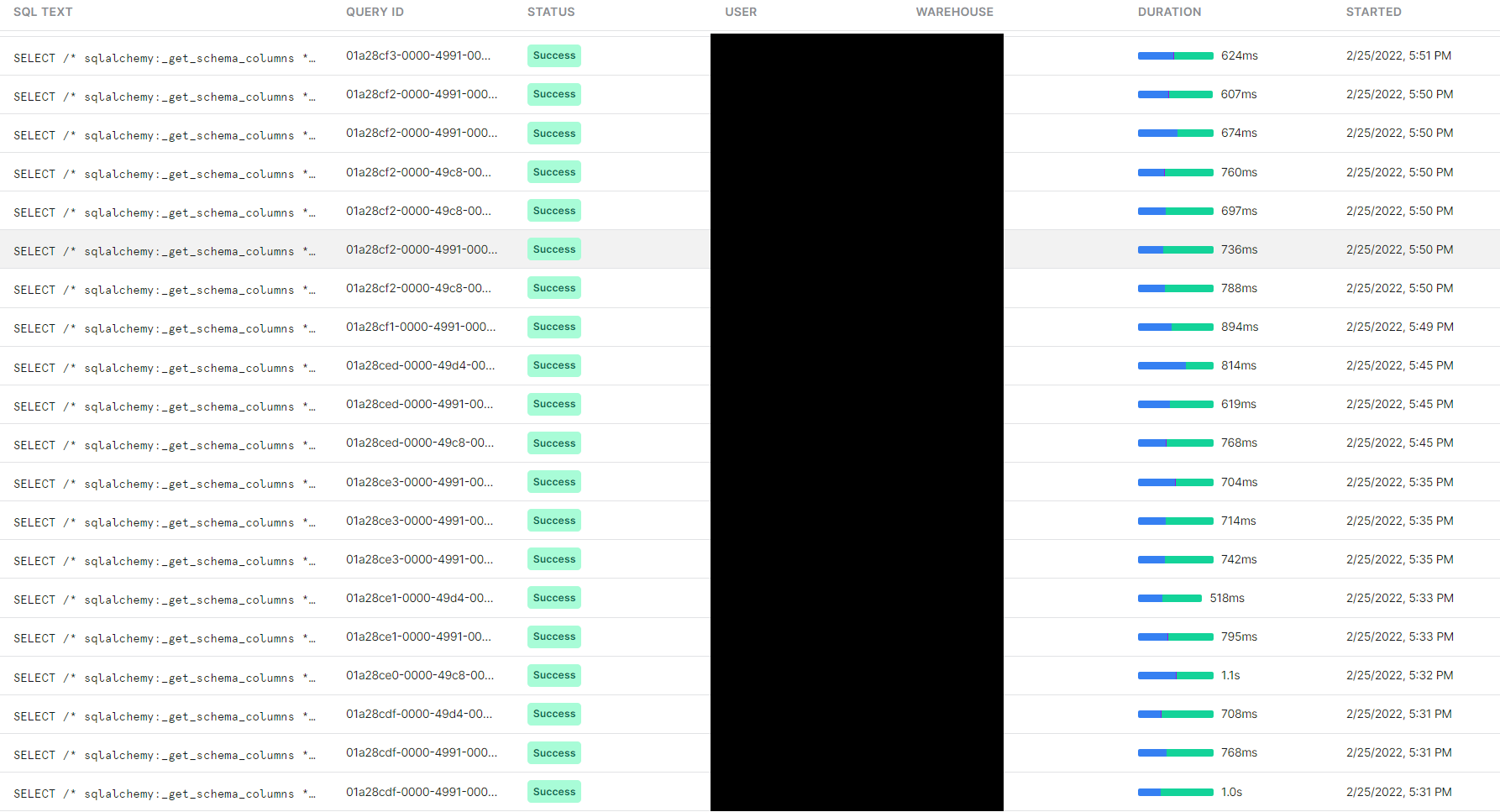
was repeated a lot, basically once per individual test. Through parametrizations, we currently have around 300 tests. These queries took anywhere from 0.3 to 0.7 seconds, but some took 1.4 and even 4 seconds. The comment on the query makes it clear that it is a query that introspects on the database: it retrieves metadata about the database instead of collecting actual data. The fact that we were doing so many introspection calls was not surprising since the tool is agnostic to the particular schema one is executing data assertions. On the other hand, it was somewhat surprising that this call was repeated for each test, given that the database is not changing. Thus, we learned that “in Snowflake, introspection calls are costly”.
While studying the code of the function associated with the query above, it shows that it should have been cached using a SQLAlchemy caching utility.
However, for some reason, in our case, that cache never seemed to survive from one test to the next.
When discussing this discovery in the team, the original author of the library suggested that perhaps a call to sqlalchemy.MetaData() could be the origin of the slow queries.
It seemed plausible since that call was made in each test.
So, since the call to _get_schema_columns was not being cached, the solution was relatively obvious: cache the call to sqlalchemy.MetaData() ourselves as follows
import functools
import sqlalchemy as sa
@functools.lru_cache(maxsize=1)
def get_metadata():
return sa.MetaData()Once we replaced the call to sqlalchemy.MetaData() with get_metadata() as defined in the snippet above, the total duration of the integration test suite against Snowflake went down to below 3 minutes.
This change brings an explicit restriction that we did not have before. Now, the database schema cannot change while executing the data assertions. Since a database storing data for analytics purposes is not expected to change its schema, this newly introduced restriction seems like a tolerable trade-off to obtain a productive test suite run.
In summary, we managed to identify and work around a performance issue while using Snowflake as a database backend. We did so by assuming schema invariance throughout the integration test suite. Making this invariant explicit reduced the execution time from 14 minutes to below 3 minutes.
Addendum:
There is an alternative hypothesis we did not test.
In our test suite, we have a sqlalchemy.Engine object as a session-level fixture, and in each test we initiate a connection to the database.
It could be possible that doing this instead of having the connection as a fixture is why the internal SQLALchemy caching gets invalidated.