- Published on
Defining ONNX graphs with Spox
- Authors
In a previous post we introduced ONNX and explained why persisting trained models in that format provides various advantages over alternatives such as Python’s pickle framework. However, we have also seen that defining an ONNX model using the primitives exposed by the canonical onnx package is cumbersome and error-prone. In this installment of our ONNX blog series we will explore a far more convenient way to define ONNX graphs using the Spox Python library.
The core abstraction behind Spox are lazy variables (Var) which can also be thought of as edges in the computational graph.
There are conceptually two ways a Var instances may be created.
The first scenario is that a Var represents an input of the model (or “argument” if one thinks of an ONNX model as a function).
The second one is that the variable represents a constant that is meant to be stored in the ONNX model.
Let’s consider the former first:
import numpy as np
from spox import argument, Tensor
a = argument(Tensor(np.float64, (3,)))
a
>>> <Var from spox.internal@0::Argument->arg of float64[3]>Spox exposes the ONNX standard through a Pythonic API.
The standard mandates that the inputs of an ONNX graph are strongly typed and have an explicit rank which is correspondingly reflected in Spox’s API.
In the above example, the argument function created a Var object representing a Tensor1 with elements of type float64 and shape (3,).
Here we chose a constant shape parameter, but this is not the only option.
We may have just as well created an argument with a dynamic dimension such as ("N", ), or with an unknown length denoted by (None,).
However, one cannot do much with a Var object alone.
For example, there is no operator overloading defined:
a + a
>>> TypeError: unsupported operand type(s) for +: 'Var' and 'Var'That is because ONNX does not define a single, unambiguous add operation.
Instead, ONNX organizes its operators into domains with versioned operator sets or opsets in short.
Opsets allows ONNX to evolve in a backward-compatible way:
Existing operators in a published opset never change, but an operator of the same name may have different semantics in a new opset.
Spox reflects this situation by exporting the standard’s opsets via versioned import paths:
import spox.opset.ai.onnx.v21 as op
op.add(a, a)
>>> <Var from ai.onnx@14::Add->C of float64[3]>We imported the opset version 21 from the ai.onnx domain, which is one of the two standard domains (the other being ai.onnx.ml).
The v21 module exposes all operators of the respective opset as free Python functions.
Naturally, users are free to use functions from different opsets in the same project.
The call to the add function produced a new Var with its correct type and shape information propagated from the inputs.
Let’s put that type and shape inference to the test by feeding invalid inputs to add:
b_i64 = argument(Tensor(np.int64, ()))
op.add(a, b_i64)
>>> RuntimeError: [ShapeInferenceError] (op_type:Add, node name: _this_): B has inconsistent type tensor(int64)We created a scalar of data type int64 and attempted to add it to our existing float64 tensor.
The add operation allows for NumPy-like broadcasting but requires both operands to be of the same generic type T which is violated in the above example.
ONNX does not define any implicit type promotion rules that may be able to resolve the situation and thus neither does Spox.
Instead, Spox immediately raises an error whenever it detects a type or shape issue.
However, a Var object is not an ONNX model yet.
Ultimately, one needs to produce a Protobuf object from the Var objects that represent the outputs of the model:
import onnx
from spox import build
b = argument(Tensor(np.float64, ()))
onnx_model = build(
inputs={"a": a, "b": b},
outputs={"out": op.add(a, b)},
)
onnx.save_model(onnx_model, "model.onnx")The above created an ONNX model that adds the arguments a and b and returns the result.
The build function binds the argument-Vars to explicit input names and the desired output Vars to output names of the user’s choosing.
Using the ever-so-useful https://netron.app/ we may visualize the created ONNX model to convince ourselves that it indeed reflects our intended logic:
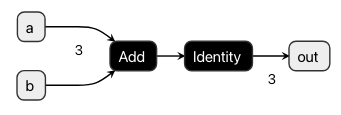
Lastly, we may use the onnxruntime to run our model:
import onnxruntime as ort
session = ort.InferenceSession("model.onnx")
out = session.run(
input_feed={"a": np.array([1, 2, 3], "float64"), "b": np.array(1.0)},
output_names=["out"],
)
out
>>> array([2., 3., 4.])As expected, we pass the inputs into the session using the names we assigned to them when building the model and the result is the expected addition.
The above example serves well as an introduction to Spox, but it is far from any actual model one may encounter in a real project. We would most commonly need to introduce some trained state into the ONNX graph as constants. Let’s consider a simple linear regression similar to the one from the previous blog post:
from spox import Var
def linear_regression(X: Var, coefficients: np.ndarray, intercept: float | None) -> Var:
mul_result = op.matmul(X, op.const(coefficients))
if intercept is None:
return mul_result
return op.add(
mul_result,
op.const(intercept),
)The linear_regression function encapsulates the logic needed to build a linear regression model akin to multiplying an input matrix with trained coefficients and optionally applying an intercept.
There are a couple of interesting aspects to the above snippet.
Firstly, it used the const function, which does not directly correspond to an operator in the standard.
It is a simplified version of the constant function which has a surprisingly cumbersome signature dictated by the standard.
Secondly, it deploys regular Python control flow in the function to return early if intercept is None.
How will the latter be reflected in the final ONNX model?
Let’s execute linear_regression to find out.
X = argument(Tensor(np.float64, ("N", 3)))
coefficients = np.array([1, 2, 3], np.float64)
result = linear_regression(X, coefficients=coefficients, intercept=None)
result
>>> <Var from ai.onnx@13::MatMul->Y of float64[N]>The type and shape inference was yet again able to propagate the correct shape and type information to result.
The string representation suggests that result was indeed produced by a MatMul operator rather than by the If-operator.
This is worth pointing out since libraries such as onnxscript parse the abstract syntax tree (AST) to convert Python code to ONNX.
Spox never resorts to parsing the AST, nor does it ever depend on type hints at runtime.
Everything is regular Python code simply operating on Var objects.
Thus, any valid Python abstraction may be used when building ONNX models with Spox.
With the linear_regression function at hand, we may now revisit the scikit-learn-like LinearRegression example from the previous post:
import numpy as np
class LinearRegression:
def fit(self, X, y):
y_offset = np.average(y, axis=0)
X_offset = np.average(X, axis=0)
self._coefficients, *_ = np.linalg.lstsq(X - X_offset, y - y_offset)
self._intercept = y_offset - X_offset @ self._coefficients
def predict(self, X):
return X @ self._coefficients + self._interceptLet’s instantiate a LinearRegression object and fit it on trivial example data as shown last time:
X_np = np.array([[0, 0, 0], [1, 1, 1], [2, 2, 2]], np.float64)
y_np = np.array([1, 2, 3], np.float64)
model_skl = LinearRegression()
model_skl.fit(X_np, y_np)As a last step, we may now use the linear_regressor function as a “converter” to build an ONNX model from the fitted model_skl object.
model_onnx = build(
inputs={"X": X},
outputs={"predictions": linear_regression(X, model_skl._coefficients, model._intercept)}
)
onnx.save(model_onnx, "model.onnx")We have again declared X as the model’s input and labeled the sole output “predictions”.
After persisting the model to a file named model.onnx we may convince ourselves that the ONNX model is functionally identical to the LinearRegression.predict method.
import onnxruntime as ort
session = ort.InferenceSession("model.onnx")
prediction_onnx, = session.run(input_feed={"X": X_np}, output_names=["predictions"])
np.testing.assert_array_equal(
prediction_onnx,
model_skl.predict(X_np)
)In the above, we have yet again created an onnxruntime.InferenceSession from the serialized model.
Subsequently, we predict from the session object and compare the results to those obtained from the LinearRegression object, which passes as expected.
Summary and outlook
Let’s take a step back after seeing this exposé of some2 of Spox’s functionality. How should one think of this library, what is its scope, and how does it fit into the wider ONNX ecosystem?
Spox exposes the ONNX standard as a Pythonic library in an explicit, unopinionated, and developer-friendly way.
It allows the user to define ONNX graphs in regular Python code using the abstractions and tools that Python offers.
However, Spox does not make decisions on behalf of the developers that would hide any of the complexities inherent to the ONNX standard.
Type promotion is the prime example in this regard.
Spox is intended as a foundational library for building further abstractions.
On a small scale, this includes defining short reusable functions such as linear_regression.
On a large scale, Spox forms the basis for entire libraries.
One such library is ndonnx, an ONNX-backed implementation of the array-API standard.
ndonnx provides a truly NumPy-like user experience and allows for converting existing array-API-compliant NumPy code - such as that found in LinearRegression.predict - to ONNX without any additional converter logic.
However, since scikit-learn and similar libraries are not yet fully array-API-compliant, there is still a need for converter libraries in the foreseeable future.
As we will see in the next post of this series, ndonnx forms a great basis for writing converter libraries.
In fact, we recommend writing converter code mainly in ndonnx rather than in Spox today.
Nonetheless, ndonnx does not eclipse Spox entirely from a user’s point of view.
Writing the best possible converter code at times requires fine-grained control over the used operators offered by Spox.
Thus, it is only logical that ndonnx and its interaction with Spox will be the next (and, for now, the last) part of the blog series on ONNX.
Footnotes
-
Sequence,Map, andOptionalwould have been other available albeit far less commonly used container types. ↩ -
Spox offers considerably more functionality than what could be show cast in a single blog post but it has comprehensive documentation. ↩