- Published on
Easily compare tabular data with TabularDelta - powered by SQLCompyre
In many data-driven workflows, both data and code changes constantly. To investigate differences caused by new data or changes in the processing logic, it is often necessary to compare tabular information in various shapes and forms. Typically, however, this requires plenty of manual effort which is both cumbersome and error-prone. To improve this workflow, we have developed TabularDelta, a generic approach to comparing data in tabular format. It has been designed to be storage format agnostic, which means that it is a great choice regardless of whether you are comparing huge tables in a relational database or investigating the difference between two Pandas DataFrames.
To further motivate the use of TabularDelta, let’s take a concrete example. Suppose you are an investor in a factory and have just received the new weekly work schedule. Not only is the new schedule sorted by initials (instead of weekdays), but it is also shorter. Now you want to find out as quickly as possible: Is this due to less demand? Will the factory be closed on specific days? Or is the reduced number of shifts just compensated by longer working hours?
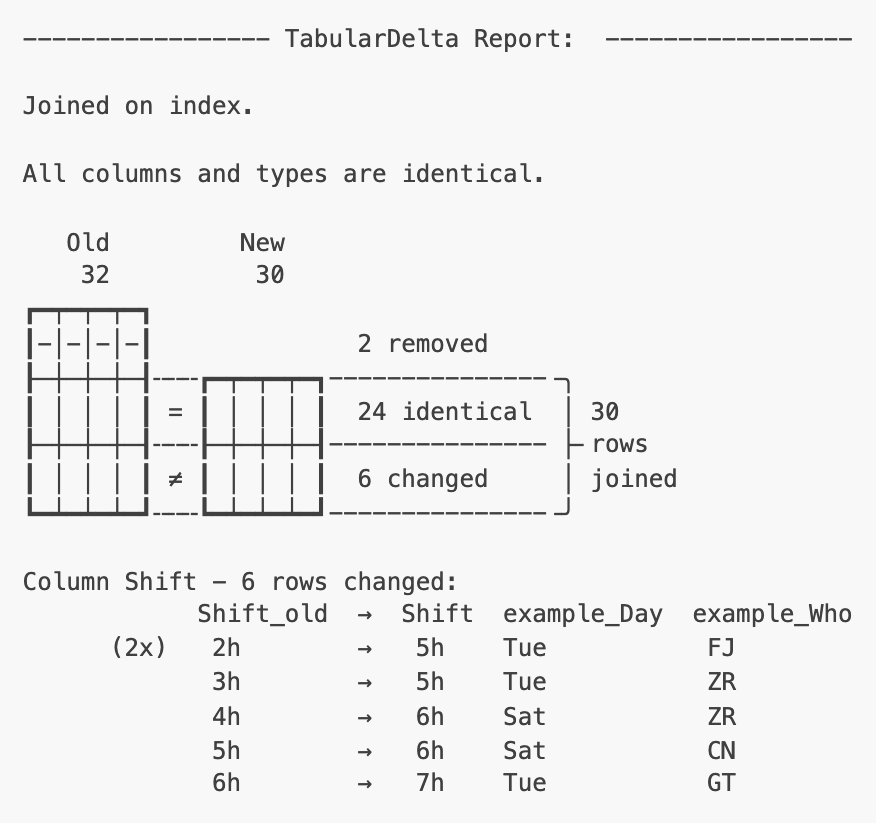
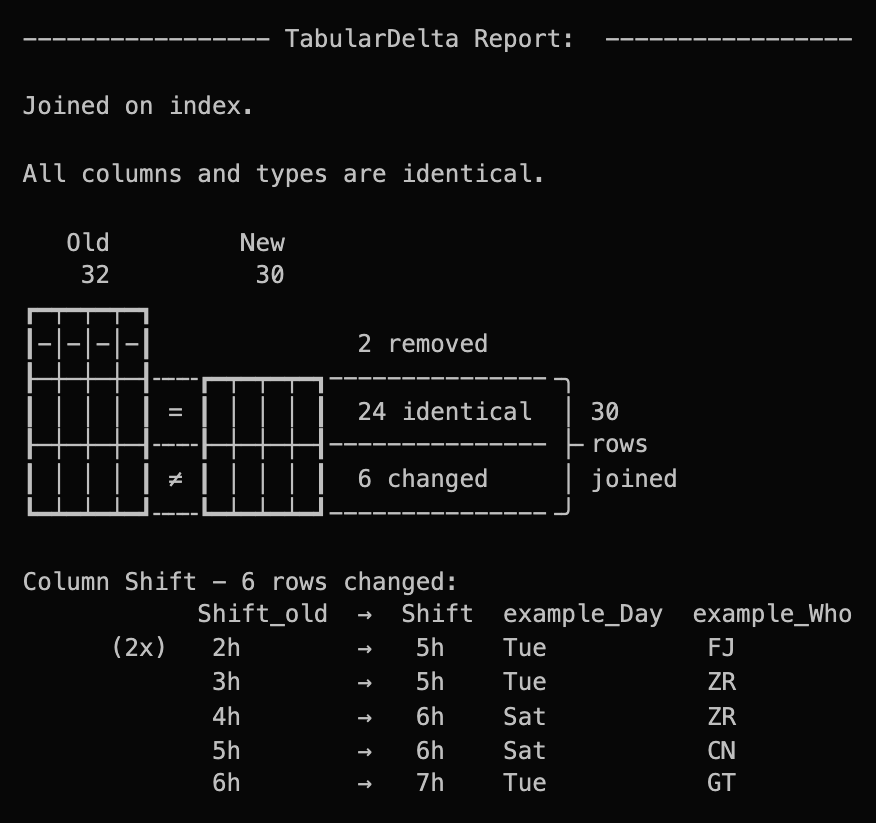
Even in this toy example, this is difficult to tell directly. And of course it would be easy to test the individual hypotheses with short manual queries. But it is even easier to look at the report below and see how the hours per shift increased without requiring any further effort.
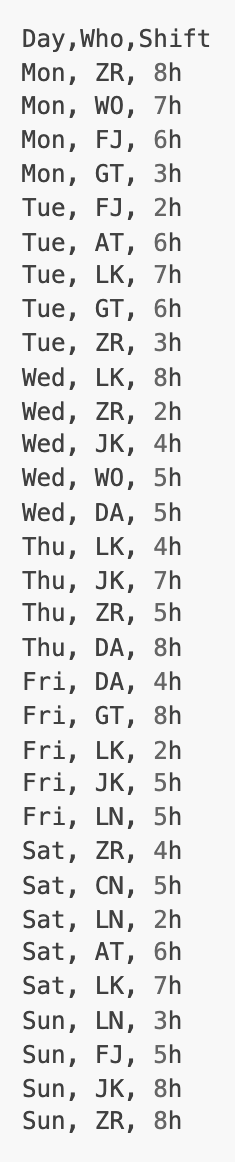  | 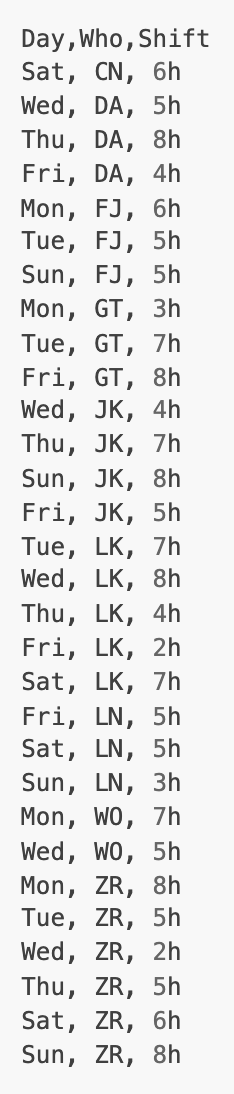  |   |
|---|---|---|
| week24.csv | week25.csv | Report |
In detail, the report shows us the following:
- Columns and data types have remained the same, which is obvious for the 3 columns here, but would not be for 30 columns.
- Two rows (shifts) have been removed.
- All other shifts still exist (30 joined), but only 24 stayed the same.
- For the remaining 6 shifts, the working hours increased.
It is easy to imagine that such a report is not only good to prevent bugs during development, but also helps enormously to get an overview of pull requests and their implications as a reviewer.
To ensure that this works not only for selected examples, but for a wide variety of table formats and use cases, TabularDelta is based on a very flexible architecture:
The concept behind TabularDelta
By separating the table comparison logic from the way of presenting the comparison results, TabularDelta offers an intuitive and powerful way to freely decide what kind of tabular information (SQL, Pandas / Polars DataFrames, etc.) you want to compare and how you want to visualize the differences.
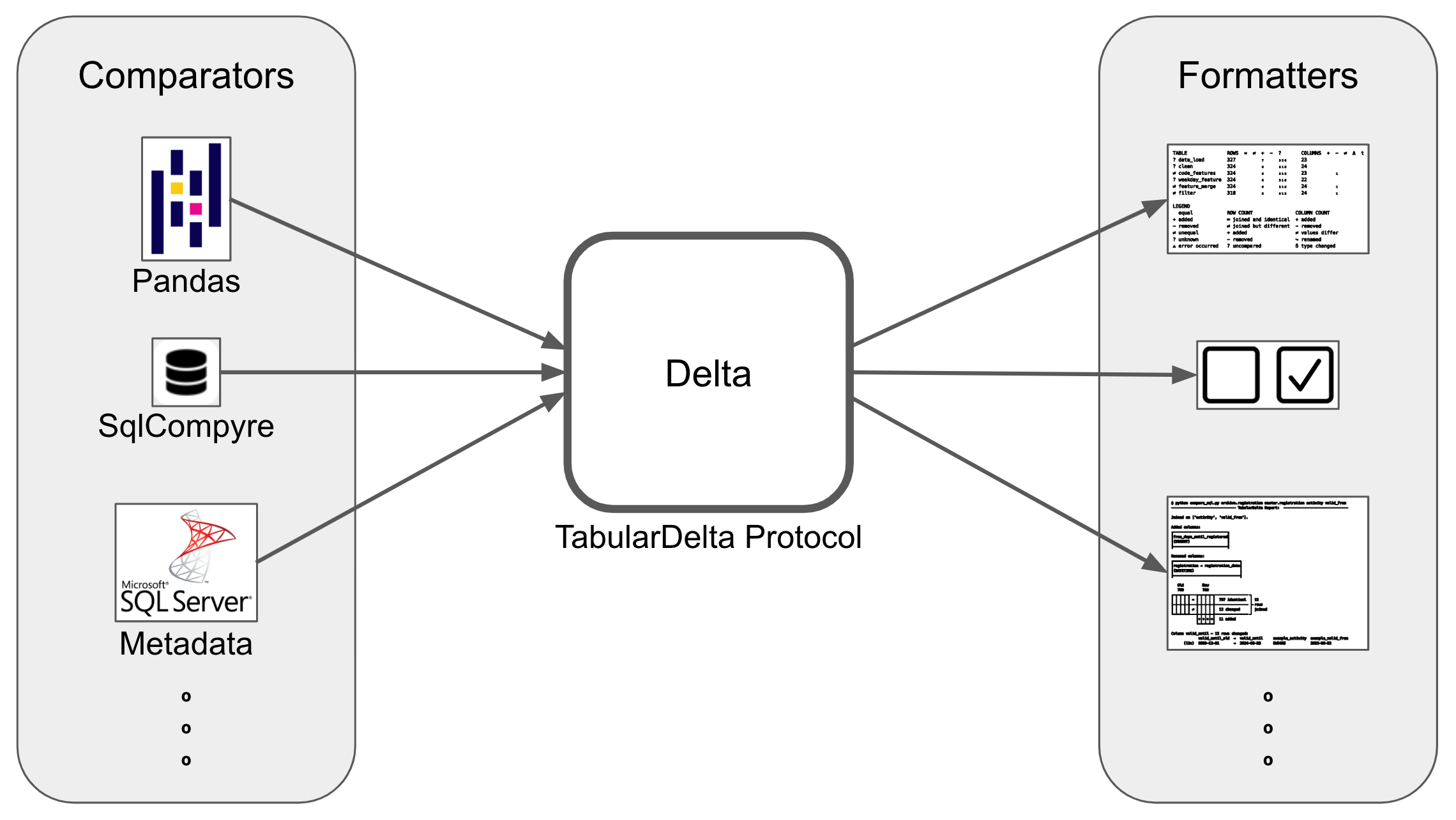
TabularDelta is a protocol that defines what information exists about a table comparison and how to access it. Since the output of all comparators adheres to the TabularDelta protocol, and formatters can handle all objects which adhere to this protocol, both using and extending TabularDelta is straightforward.
Using TabularDelta is simply a matter of selecting the correct comparator for the available data formats, and choosing the optimal formatter to answer existing questions. If the available data is not yet supported, you can just add new comparison logic and can benefit directly from all formatters. Similarly, if the visualisation is inadequate for the task, you can just implement a new output format that can be used directly for all types of tables.
The following comparators are already implemented and support various data formats out-of-the-box:
SqlCompyreComparator: This comparator is a wrapper which uses SQLCompyre to create a comparison result. SQLCompyre is a powerful tool for comparing SQL Tables which not only predates TabularDelta, but was one of the main inspirations for it. It is open-sourced together with TabularDelta, and described in more detail below.
SqlMetadataComparator: Repeatedly comparing a large number of huge tables using SQLCompyre leads to delays. The SqlMetadataComparator uses DBS-specific metadata to achieve the best possible comparison in O(1) with regards to the number of rows. At the moment this is only implemented for MsSql Server, but can easily be extended for other DBSs with just a few lines of code.
PandasComparator: This comparator compares two DataFrames. Since many tabular formats support the conversion to Pandas DataFrames, and Pandas itself offers a variety of import options, this can also be used for CSV, Polars, Excel, JSON, Parquet, etc.
Based on what you want to do with the comparisons, you can currently choose between two different formatters:
DetailedTextFormatter: The goal of this formatter is to get as many details about a single comparison without losing the overview.
OverviewRowFormatter: This formatter is stateful, and collects comparisons as rows.
Calling table() will combine all comparisons into a single table.
Additionally, add_header, add_row, and add_legend allows to extend the visualisation with additional information.
Using TabularDelta
With this in mind, we can now return to the example from above.
Given the two CSV files week24.csv and week25.csv, we want to learn something about the differences.
Instead of manually checking multiple hypotheses for the changes with queries,
we use the features that TabularDelta provides out-of-the-box.
Although there is no CSV comparator, Pandas natively supports the reading of CSV files,
which is why we choose the PandasComparator.
Since we want to have an overview of a single comparison, we use the DetailedTextFormatter.
After executing these few lines of code, we get the detailed report that you saw at the beginning.
import pandas as pd
from tabulardelta import PandasComparator, DetailedTextFormatter
df_old = pd.read_csv("week24.csv", index_col=[0, 1])
df_new = pd.read_csv("week25.csv", index_col=[0, 1])
delta = PandasComparator().compare(df_old, df_new)
print(DetailedTextFormatter().format(delta))For further examples, support and information on development, please take a look at the TabularDelta documentation.
The idea behind TabularDelta was largely inspired by another exciting project called SQLCompyre, which we had been using for SQL table comparisons, long before it was wrapped as a comparator for TabularDelta.
SQLCompyre
SQLCompyre was developed as a standalone Python package for efficiently analysing differences in SQL tables, schemas and entire databases. The package is built on top of SQLAlchemy and designed to be dialect-agnostic, which allows it to support a wide range of SQL databases out-of-the-box.
The two main reasons that make it widely applicable to anyone who regularly works with relational databases are its user-friendly interfaces and adoption of a lazy evaluation strategy. The interfaces are available both programmatically in Python and can also be called up via a CLI. Regardless of which one you choose, you can achieve insightful analyses in just a few steps. Data is only loaded and compared when necessary. Results are cached and computations are not repeated unnecessarily. This has several advantages:
- Even large tables can be compared well, especially if there are only specific questions to be answered.
- You can interactively explore the differences between tables without being held up before or in between analyses.
- Less time is wasted when performing similar or extended analyses, as partial results can be cached.
To get started with comparing tables (or entire schemas), all you need is a sqlalchemy engine:
import sqlalchemy as sa
engine = sa.create_engine("<connection string to your database>")Then, you can call one of the methods from the (small) public API of SQLCompyre, for example:
import sqlcompyre as sc
comparison = sc.compare_tables(engine, "schema_1.table_a", "schema_2.table_a")Due to the laziness of SQLCompyre, no comparison between the tables has been performed yet.
SQL queries are executed only once properties on the comparison object are evaluated.
For example, we might want to get information about the absolute difference in row counts between the tables via comparison.row_counts.diff.
Another example would be the comparison.row_matches.n_joined_unequal which provides the number of unequal rows when joining on the tables’ primary keys.
In many cases, we don’t, however, know exactly what we’re looking for between the tables and simply want to know if there are any differences. To this end, SQLCompyre allows to generate a summary report for the comparison:
report = comparison.summary_report()You can then print this report or write it to a file for further inspection.
For even more interactivity, plenty of properties on the comparison object return SQLAlchemy Select clause
which allows to further augment the queries that are prepared by SQLCompyre.
One example would be to further filter the rows which are considered unequal between two tables:
comparison.row_matches.joined_unequal can be further modified with the
SQLAlchemy expression API.
More examples, support and information on development, can be found in the SQLCompyre documentation.
The use of SQLCompyre gave rise to the idea of having similar functionalities for other data formats as well. Although it would have been possible to create a PandasCompyre, PolarsCompyre and CsvCompyre, this approach would have led to scaling and maintenance problems because new analyses, visualisations and interfaces always had to be re-implemented in all projects.
This is why we decided to create TabularDelta, which is a generic approach to comparing data in tabular format.
Ultimately, both tools remain huge productivity boosters, whether you opt for the flexibility of TabularDelta or the interactivity of SQLCompyre, so feel free to give them a try!